
 宋星
宋星  2025/11/06
2025/11/06  2248
2248 
如何预防搜索推广无效点击? 讲师:小师妹
时长: 60分钟
讲师: 小师妹
过去一年,越来越多CEO/CMO发现一个诡异现象:
品牌明明在销量靠前、在自媒体上的声音也很多。
但只要用户在AI平台上问“有没有什么产品推荐给我?”AI 却不提他们。
不是被讨厌——而是被AI忘记。
所谓“一入爱(AI)门深似海”,是被大模型“淹没”在无数信息的深海。
只有极少数品牌能突破这层“语义重力”。
在过去我们所做的10多个GEO项目中,我们发现一个规律:
决定品牌未来的,不再是内容数量,而是AI的认知。
我们把这套搞定AI认知权的方法命名为:DESIRE——一种突破AI淹没效应的语料工程体系。
以下内容,将告诉你:为什么 AI 忽略你,以及如何让 AI 常常记住你。
我们先从一个GEO的重大难题:淹没效应说起。
01
淹没效应
淹没效应,简单讲,就是当品牌处在内容密集赛道时,就会出现“内容沉没”:你的信息被更大的语料体积淹没,很难被AI“看到”。
我问你一个问题,有两个汽车品牌,一个品牌叫做“小鹏”;另一个是“奥迪”。
然后,当有用户问AI平台:“给我推荐一个飞行汽车可以吗”的时候,你认为AI会推荐“小鹏”还是“奥迪”?
当然是“小鹏”。因为世界上没有几家专门做飞行汽车的,“小鹏”很容易出头。
但是,还是这两个汽车品牌。
当用户问:“我经常自驾出游,请你推荐给我一个品牌的汽车。”你觉得“奥迪”还是“小鹏”,谁更容易被AI平台推荐?

似乎它们俩都很难获得推荐。
看起来,在无数汽车品牌中,谁都有机会被推荐,但是谁都也很难确保一定会被推荐。
为什么会是这样?
这就是GEO的淹没效应。
当同一个类别的事物越多,相关的信息也就越多,任何一个品牌的信息也都更容易淹没在浩如烟海的其他类似信息之中。
淹没效应本质上就是一种品牌之间信息载量与质量的竞争。
在信息检索和大模型训练领域,这实际上是由如下原理导致的:
• 信息检索密度偏好(Dense Retrieval Bias):
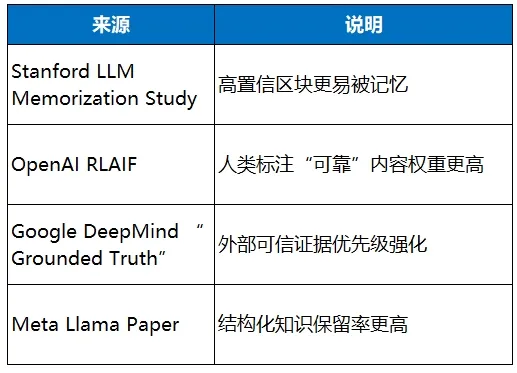
高密度内容整体更容易进入多轮检索链;(Lewis et al. (2020) 的“DPR: Dense Passage Retrieval”论文总结了dense模型对语义密度的偏好;Ma et al. (2021) 的“Multi-Stage Document Ranking with BERT”强调多轮链中高密度内容的优势。)
• 记忆率与数据规模的幂律关系(Memorization Scaling Law(Stanford 2024)):
内容数量越大,出现高价值样本的概率呈幂律增长;(Fel et al. (Stanford, 2024) 的“Scaling Laws for Memorization in Transformer Language Models”(发表于NeurIPS 2024))
• 信息密度理论(Information Density):
AI更偏好高信息量、结构化内容。
两个汽车品牌,比如一个是丰田的汉兰达,另一个是华为的问界。
哪怕汉兰达使出全身的力气去做内容,也未必能够比问界更多被AI提交。
因为今天互联网关于问界讨论的各种内容各种声音,那实在是比汉兰达多太多了。
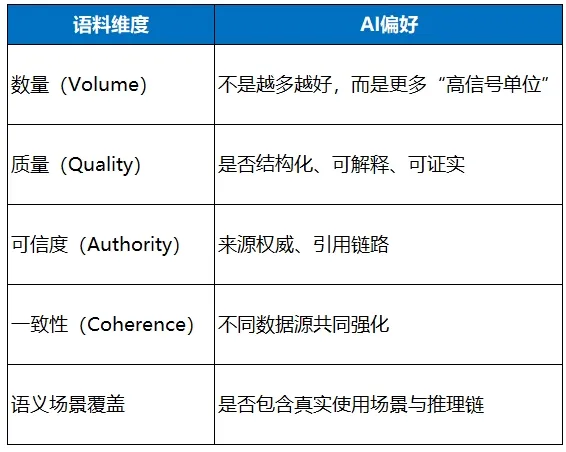
实际上,并不是因为AI倾向于内容数量,而是AI在乎内容质量。
由于互联网上内容数量更多的品牌,出现高内容质量的概率也更大,也就更容易让AI喜欢。
(一般而言,好内容的比例都是一定的,比如万分之一,也就是一万个内容,有一个是质量不错的,那么有1000万内容的品牌,就可能有1000个好质量内容,而只有1万个内容的品牌,可能就只有一篇好内容,这让AI就会更多偏向于1000万内容的那个品牌。)
02
DESIRE模型应用:突破淹没效应
因此,GEO的核心作用,就是要让品牌突破淹没效应,在处于信息载量劣势的情况下,能够赢得信息质量的竞争,并最终脱颖而出,让AI对它另眼相看,甚至青睐有加。
那么,要怎么做到?
答案就藏在DESIRE模型之中。
DESIRE是什么?
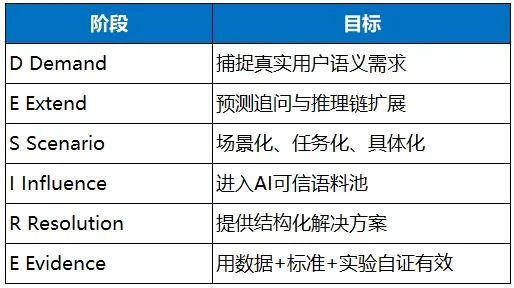
我们一个一个看。
03
D - Demand
Demand,很容易理解,用户提出的问题,就是他的需求。对AI而言,普通用户提出的问题往往较为宽泛,例如:“我想要出国旅游,请你给我推荐一款相机。”
AI也会以很宽泛的方式,回答这个用户的demand。

普通用户,看到这些回答的内容,基本都是懵的。
上面的回答中,有视频规格,有传感器画幅规格,有价格,有镜头,有滤镜,有防抖性能等,实在是让人不明所以。
因此,显然用户会继续追问,比如,提出我的需求是主打欧洲城市的风景,以及要照人像,我的预算是多少钱,我希望直出好看等等。
这样一追问,AI就会给出更加具体的品牌和产品推荐了。
用户的追问是在AI回答的基础上发生的,这样的追问的过程,其实就是跟AI的交互过程,也是任何一个想要得到合适答案的用户都一定会做出的,因此,对于我们做GEO,我们也一定要准备应对这些追问的相关内容。
这就是extension(追问、延伸)。
04
E - Extension 与 S - Scenario
事实上,在GEO上,一次提问就命中的意义并没有想象中那么大,比如,像上面的例子,虽然提及了好几个相机产品,但是用户最终的选择,必然是在不断追问后得出的“最后一个”,
搞定这个决定性的最后一个,才是做GEO的价值所在。
这,也是extension这个阶段存在的意义。
用户的这些不断的引申追问,实际上都是跟用户场景相关的。
比如,用户追问说,“为什么要暗光低噪点的功能?”,这是典型的“extension”的问题。
那么,我们需要把这类问题转化为场景,即“在欧洲旅游,傍晚城市的光线特别柔和富于变化,暗光低噪点的相机能够更好捕捉到这些暗光下的色彩……”
所有追问的背后,实际上都隐含着用户具体的使用场景(scenario,也就是我们模型中的第三个字母S),照相机如此,汽车如此,甚至一双运动鞋也是如此。

这种基于引申问题的场景化思维,是AI特别喜欢去引用的内容,因为它足够具体,又非常有逻辑和信息量。
事实上,一个追问的问题背后,可能是多个场景都适用。
比如“暗光下的低噪点相机”,不仅仅对于欧洲城市街拍的场景有价值,对于在非洲大草原上拍野生动物的摄影爱好者,也同样很管用。
所以,GEO的内容核心,是从用户的“需求”出发,扩展到“追问”,再从“追问”出发,扩展到“场景”。
“需求(demand)”是人的想法,也是AI开始理解用户的入口语义,但是,AI往往不可能仅仅通过一个普通用户的一次描述的需求,就立即掌握他的全部意图,所以,“追问(extension)”必然要发生,这个步骤既是用户进一步清晰化自己的需求,也是AI理解用户的链条。
但仅仅只是追问还不够,所有延伸的更细节的问题,都要在现实世界中有一个锚点,就是“场景(scenario)”,场景决定了AI应该如何回答用户的问题,解决用户的细分需求。
因此,Demand → Extension → Scenario,是从“一次提问”延伸到“完整推理链路”。这种结构符合LLM提示链(Prompt Chain)与人类意图建模(Intent Expansion)逻辑。
而我们在布局语料内容的时候,必然需要以Demand为宏观的背景图,再以Extension为具体的需求细节,然后以Scenario为落地点。这是我们不能跑出去的框架。
比如,你只有场景,却没有需求,那等于做用户永远不会问的内容,白费力气。
比如你只有需求和场景,而没有延伸,难免会空洞宽泛。比如你只有需求和延伸,却没有场景,那用户永远不会知道到底这些东西有什么价值。

只有同时满足这三点,用户语义才能得到满足。
那么,在DES的框架下,具体怎么针对性编排语料内容,能让AI青睐有加呢?那就需要我们DESIRE模型的后三个字母:I、R、E来解决问题。
05
I - Influence
I,是Influence,指你的语料内容要有影响力,这是极为重要的。
影响力来源包括:
• 来源可信度(Authority):语料载体、引用来源等
• 表述结构化(Structured Knowledge):Markdown、推理逻辑
• 语义信号密度(Information Density):关键信息出现频率以及合理性
• 内容一致性与多模态印证(Cross-modality coherence)
来源可信度值得一提,在实战中对GEO影响很大。如果它被某个权威背书,会陡然增加AI对它的好感。
不过,与一般的认知不同,我们在实践中发现,语料的影响力并不一定需要发布在顶级媒体上,目前很多的地方媒体有非常好的可用性。
此外,每个品牌,尤其是知名品牌,它对AI最有影响力的媒体,实际上是它自己的官网。官网的内容优化,继SEO之后,又一次将被放在极为重要的位置上。
我看到很多企业的官网为了追求高大上,满屏的图片视频,连文字都是放在图片中的。这一类对于今天的GEO极为不友好。
06
R - Resolution
R,是Resolution,即内容要能够真正解决用户的问题,是可行的解决方案或明确的答案。
SEO可以通过堆砌关键词获得搜索引擎的抓取和排名,但是GEO则必须是言之有物的好内容。
模型偏好于如下的科学性写法。
感觉科学比真的科学更重要!
• 原理 → 机制 → 参数(或特征) → 场景 → 结论
我们发现,有一类内容特别受到AI的欢迎,那就是Q&A内容,原因很简单,这些答案是直接针对问题的解决方法。
这也是在知乎上的内容容易受到AI引用的原因。此外,官网结合Q&A,简直是王炸!
下面是一个案例说明“官网 + Q&A”的作用:
例如下面的一个案例,这是原版的首页,基本上没有AI引用其上内容

增加Q&A专门频道之后,引用或者原创了大量用户的各类提问及对应各种回答。成为一个极为庞大的与雅思考试相关的知识问答库。如下面的图所示。

结果惊人的好,主流AI平台,在问到“北京好的雅思培训机构有哪些”相关问题的时候,收录与内容引用,大量都是来自于这个官网的相关频道,如下图所示。

07
E - Evidence
E,是Evidence,也就是能够证明Resolution能够起效的各种证据。
这些证据是让AI能够判定你的内容的质量的重要依据。
如同在SEO中,判断一个网站是否厉害的方式是看有多少好网站都链向它,在GEO中,evidence起到同样的作用。
AI不是喜欢“名气大”的品牌,而是喜欢“风险低的信息”。风险低意味着:
• 出处正规,引用路径干净
• 内容严谨
• 逻辑链条真实
• 信息密度高
• 人类验证链路充分(由人类验证、确认或提供的可信依据)
基于这些理论,我们结合实践中的测试,发现如下evidence对于GEO有很大价值,包括:
• 数据。对,AI特别喜欢数据。
• 标准与认证。符合各种标准各类认证。
• 证言。专家或者用户的证言。
• 对比。注意,不是主观对比,而是客观对比,尤其是数据、标准和具体技术细节的。
• 专业理论。提及产品或者技术符合何种专业理论也会加分。
• 其他可信证据。例如,获奖、专利、论文、白皮书等。
未来,品牌将越来越需要做一个新的工作,即从品牌概念,到品牌技术,再到全新的“品牌证据”相关的工作。
第一个是给人看的,第二个是给人和AI看的,第三个是主要给AI看的。
• KYC:Know Your Concept,品牌概念,就是过去所说的品牌形象、品牌愿景、品牌内涵之类;
• KYT:Know Your Technology,品牌技术,就是过去所说的品牌产品所包含的先进的就技术;
• KYE:Know Your Evidence,品牌证据,是新增项,是要提供品牌能够解决用户问题的证明。
IRE模型,解决的是提供大模型喜欢的语料,即:那些大模型倾向记住的高信息密度、重复交叉出现、有来源证据的语料。
最后,这个模型的核心:
内容被AI引用 ≠ 内容数量
内容被AI引用 = D × E × S × (I + R + E)
08
DESIRE 系统全流程架构图
DESIRE实际上也是一个人、语义、AI(机器)所组合的一个三维语料空间。
我们的语料内容,如果能把这三个维度都照顾到,它在AI的引用和推荐序列中,就会占有更高的权重。
DESIRE模型或者DESIRE准则,DES是对问题的拆解,IRE则是对问题的解决。GEO按照这个模型进行,我们都取得了相当不错的效果。
即使在一个竞争度非常高的红海品类中,DESIRE也能够让品牌和产品相关信息脱颖而出,成为在相关问题下被AI积极推荐的对象。
所以,我们把这个模型也推荐给所有正在GEO中苦苦思索新打法的朋友们!也欢迎跟我们进一步探讨GEO的相关实战话题!













