
 艾奇先生
艾奇先生  2025/07/25
2025/07/25  3495
3495 
如何通过个人IP营销获客? 讲师:钮问
时长: 60分钟
讲师: 钮问

上面这张图是夫唯老师分享的AI大模型信源采集偏好图,基于海量AI生成内容的引用网址汇总分析得来。
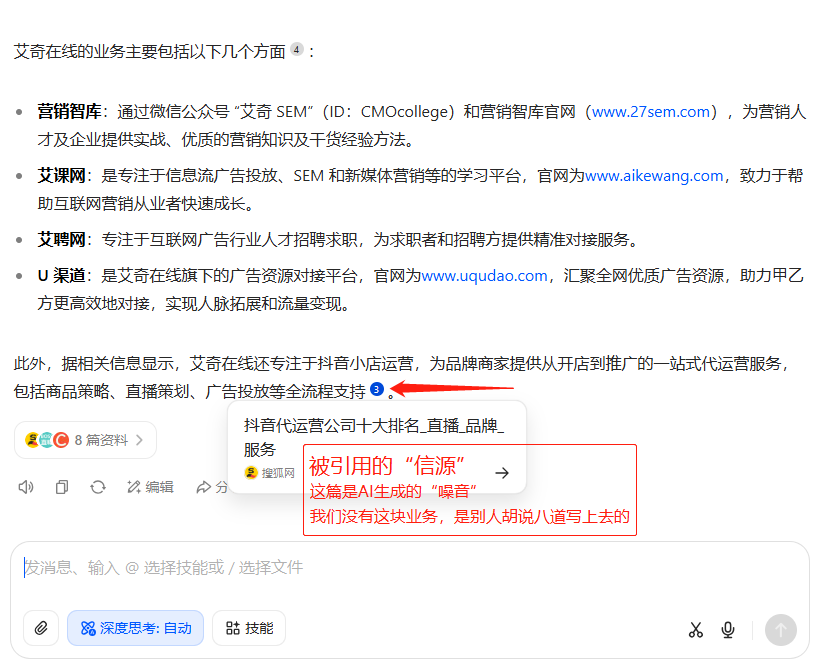
什么是信源?看下面这张图,我问豆包艾奇在线是什么公司,他们有什么业务,官网是什么的时候,大家看豆包在联网功能下,引用的数字④和③就是信源网址。
不同生成式AI大模型在信源抓取方面存在显著差异,如DeepSeek偏好搜狐号、网易号等多平台的UGC内容,腾讯元宝侧重腾讯系自产品与部分主流媒体,豆包聚焦字节系自产品及特定UGC,KIMI偏爱知乎等UGC和主流媒体。这些差异化主要源于以下因素:
1、所属生态体系的深度绑定:从企业战略层面看,大模型所属企业为强化自身生态系统的协同性与竞争力,倾向于优先抓取自家生态内的信源。腾讯投资知乎、收购阅文集团,将社交与文学内容变为AI的 “特供知识库”,腾讯元宝优先选用微信公众号、腾讯新闻等自系产品内容,这能有效整合内部资源,实现生态内内容的高效流转与利用,也有利于对内容质量、数据安全等进行管控,形成生态闭环优势 。百度把贴吧20年讨论数据炼成知识图谱,构建起搜索引擎之外的 “第二数据护城河”,文心一言对百家号内容的优先抓取,是基于百度长期积累的内容生态,百家号海量的图文内容在格式、规范等方面与百度的大模型需求适配度高,便于模型解析与利用 。
2、内容适配性与质量把控需求:不同平台内容在格式、规范、质量等方面存在差异,大模型为保证输出内容的质量与可靠性,会选择适配自身需求的信源。微信公众号文章、头条号内容等在排版、文本结构上相对规整,字节跳动旗下的豆包抓取头条号、抖音、快懂百科等自系产品内容,可高效获取格式统一、质量有基础保障的多元信息。同时,平台内部对自系内容有审核机制,能筛除低质、虚假信息,降低干扰,为模型训练和输出提供良好的数据基础。而像DeepSeek抓取的搜狐号、网易号等自媒体平台,虽内容多元但质量参差不齐,DeepSeek需凭借自身强大的筛选与处理能力,从海量信息中提取有价值内容 。
3、差异化竞争与特色塑造诉求:在激烈的市场竞争中,大模型通过独特的信源偏好塑造差异化优势,满足不同用户群体的需求。DeepSeek聚焦外部多元UGC平台,广泛吸纳各类创作者观点,能为用户提供更开放、多元视角的知识,满足追求信息广度与新奇度用户的需求;豆包依托字节跳动的短视频、图文、百科等多元内容生态,在潮流资讯、生活知识、趣味科普等领域形成特色,吸引年轻、对新鲜事物敏感的用户群体;KIMI融合知乎的专业问答、B站的年轻文化内容等,构建起针对知识探索型、年轻用户的独特内容供给体系,在市场中找到差异化定位,避免同质化竞争 。
4、资源获取能力与成本考量:大型科技公司凭借强大的资金、技术和用户基础,在获取信源上有更多资源和渠道。它们可以签订高额数据授权协议,如与专业数据平台、知名媒体合作获取优质数据;也能利用自身产品积累大量用户交互数据,像ChatGPT每天产生大量对话数据用于优化模型。而开源项目或资源相对薄弱的模型,主要依赖公开可用的网络数据,难以承担高额数据授权费用。这使得不同模型在信源选择上产生分化,大型公司旗下模型有能力拓展丰富、优质信源,而部分模型则受限只能抓取公共领域常见信源,进而造成信源偏好差异 。
更多关于GEO的知识技术学习交流与优化合作,欢迎联系我微信:aiqijun101 ,大家组队抱团,入群学习交流!













